

Hyperspectral image clustering |
Classification of HSIs is a challenging task that has attracted considerable attention in HSI understanding during the last decades. One of the issues that frequently arises in the processing of HSIs is the partial or total lack of ground truth information. A common way to deal with this issue is to resort to unsupervised classification, i.e. clustering. We introduce two novel possibilistic clustering algorithms, which utilize the concepts of sparsity and parameter adaptivity. First, a suitable sparsity constraint is imposed on the degree of compatibility vectors of the data points (hyperspectral image pixels), which forces each data point to be compatible with only a few or even none of the clusters, giving rise to the sparse PCM (SPCM) algorithm. As a result, SPCM is, in principle, capable of identifying very closely located clusters of possibly various densities. However, SPCM requires a good initial estimation of its involved parameters, in order to perform well, due to the fact that they remain fixed during its execution. |
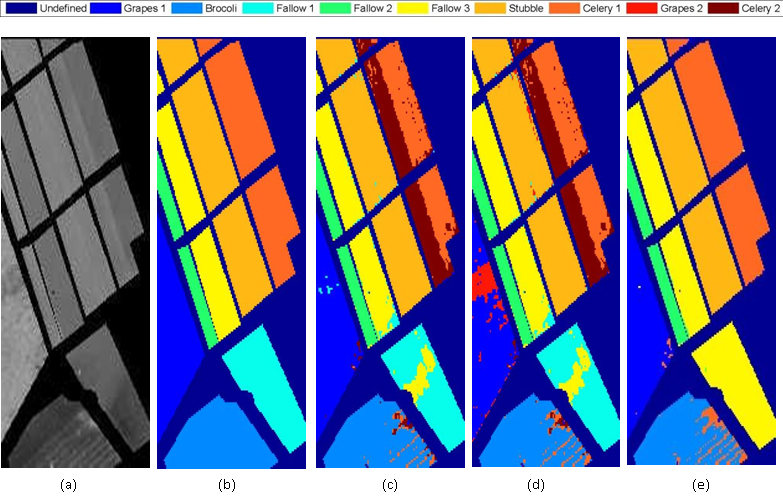 |
Figure: (a) The 4th PC component of AVIRIS Salinas Valley HSI and (b) the corresponding ground truth labeling. Clustering results of Salinas HSI obtained from (c) APCM (8 clusters), (d) SPCM (6 clusters) and (e) SAPCM (9 clusters). |
In order to deal with the previous problem, SPCM is further extended using the rationale of the adaptive PCM (APCM), based on which the parameters of the algorithm are properly adjusted during its execution. Such an extension gives rise to the so called Sparse Adaptive PCM (SAPCM) algorithm. A consequence of this parameter adjustment is that, given an overestimate of the true number of clusters, the algorithm has (in principle) the ability to reduce it gradually towards the true number of clusters, i.e., the algorithm is able to estimate by itself the actual number of clusters as well as the clusters themselves. This contrasts with the majority of the state-of-the-art clustering algorithms, which require exact prior knowledge of the number of physical clusters underlying in the data set, in order to be able to perform well. Furthermore, SAPCM algorithm is immune to noise and outliers, as its predecessor SPCM and improves even more the estimates of the cluster representatives. |
Publications:
|
Achievements